Thực nghiệm đánh giá YOLOX cho bài toán phát hiện đối tượng tài liệu
Trong vài thập kỷ qua, với sự gia tăng nhanh chóng trong việc số hóa các hình ảnh tài liệu, việc trích xuất thông tin chính xác là một trong những hướng nghiên cứu quan trọng. Với sự phát triển của phát hiện đối tượng, nhiều nghiên cứu ra đời hướng đến việc phân loại tài liệu dựa trên nhiều thành phần của trang tài liệu đó.
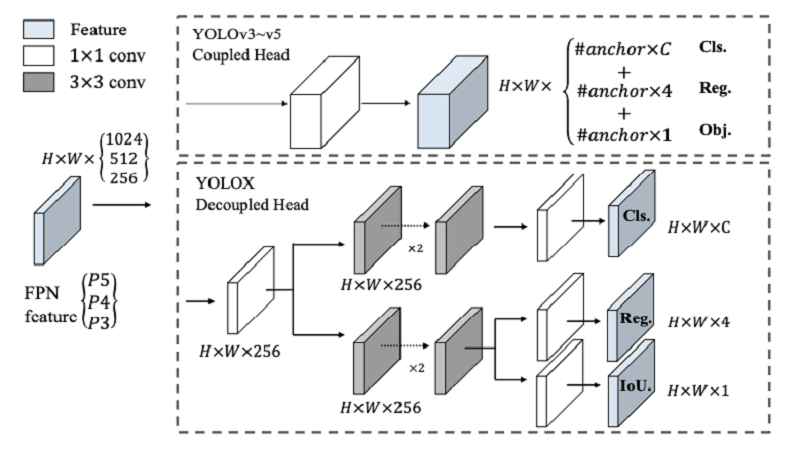
Mục tiêu của nghiên cứu này là đề cập đến bài toán POD (Page Object Detection) – phát hiện đối tượng xuất hiện trong trang tài liệu thông qua đánh giá 2 bộ dữ liệu IIIT-AR-13K và UIT-DODV dựa theo phương pháp YOLOX. YOLOX đạt kết quả 69,0% mAP, tốt hơn 2,90% so với kết quả mô hình one-stage cao nhất – YOLOv4- mish được công bố trên bộ dữ liệu UIT-DODV. Trong khi ở IIIT-AR-13K, YOLOX đạt được 66,9% mAP và thấp hơn nhiều so với các phương pháp two-stage đã công bố trước đó. Bên cạnh, những phân tích về độ hiệu quả của phương pháp state-of-the-art YOLOX cho bài toán POD cũng được cung cấp, là tiền đề cho những nghiên cứu tiếp theo trong tương lai.
Qua nhiều thế kỷ, tài liệu giấy vẫn là công cụ chính để tạo nên sự tiến bộ lâu dài của loài người. Ngày nay, hầu hết thông tin vẫn được ghi lại, lưu trữ và phân phối dưới dạng giấy. Việc sử dụng máy tính để chỉnh sửa tài liệu và sự ra đời của bộ xử lý văn bản vào cuối những năm 1980 đã thay thế tài liệu truyền thống (giấy, tờ báo, sách,...), tài liệu số (WORD, PDF...) xuất hiện dẫn đến sự gia tăng nhanh chóng trong việc số hóa tài liệu và cải thiện đáng kể khả năng tiếp cận dữ liệu và được lưu trữ thông qua các dịch vụ điện toán đám mây để thuận tiện cho truy cập, tìm kiếm, sao lưu tài liệu (Marinai, 2008). Bên cạnh những thuận lợi đó là khối tài liệu khổng lồ dẫn đến việc truy cập trở nên khó khăn hơn. Với các thuật toán phát hiện đối tượng dựa trên học sâu gần đây trong lĩnh vực thị giác máy tính, một lượng phương pháp đáng kể được phát triển đã xây dựng mô hình phát hiện các đối tượng trang đồ họa trong hình ảnh tài liệu như một vấn đề phát hiện đối tượng (Bhatt et al., 2021). Dựa theo sự phát triển đó, phạm vi của nghiên cứu này là bài toán phát hiện các thành phần quan trọng xuất hiện trong trang tài liệu như “Caption”, “Table”, “Figure”, “Formula”, ... “Document Image Understanding” (Gao et al., 2017) là một nghiên cứu quan trọng được thực hiện với nhiều vấn đề thách thức, đang nhận được sự quan tâm ngày càng nhiều không chỉ từ các cộng đồng phân tích và ghi nhận tài liệu. Bài toán phát hiện đối tượng trang trong hình ảnh tài liệu (Nguyen et al., 2018; Long và ctv., 2020; Le et al., 2021; Nguyen et al., 2022) vẫn là một thách thức vì các đối tượng trang rất đa dạng về quy mô và tỷ lệ khung hình, và một đối tượng có thể chứa các thành phần gần như tách rời nhau. Do đó, việc rút trích thông tin từ hình ảnh của tài liệu là vô cùng cần thiết, nhiều phương pháp máy học ra đời trong tương lai sẽ giúp con người dễ dàng tìm kiếm những tài liệu cần thiết và tránh mất nhiều thời gian. Hướng giải quyết của những phương pháp được đề xuất trước đây chưa mang lại độ chính xác cao và tốn nhiều thời gian để xử lí. Dựa theo nhiều công trình nghiên cứu khoa học trước đó và đứng trên góc nhìn của bài toán phát hiện đối tượng, bài báo này là bài toán phát hiện đối tượng trang (Hình 1) được đề cập thông qua việc đánh giá 2 bộ dữ liệu IIIT-AR-13K (Mondal et al., 2020) và UIT-DODV (Dieu et al., 2021) dựa theo phương pháp YOLOX (Ge et al., 2021). Sơ lược về các bộ dữ liệu sử dụng trong bài toán, bộ dữ liệu IIIT-AR-13K (Mondal et al., 2020) chứa tổng cộng hơn 13,000 hình ảnh trang được chú thích với các đối tượng thuộc 5 danh mục phổ biến khác nhau gồm “Table”, “Figure”, “Natural image”, “Logo” và “Signature”. Mondal et al. (2020) đã tạo bộ dữ liệu này theo cách thủ công bằng việc sưu tầm rộng rãi từ các bài báo cáo, tạp chí khoa học, bài nghiên cứu khắp nơi trên thế giới và đây là một trong những bộ dữ liệu lớn nhất trong lĩnh vực phát hiện đối tượng trang đồ họa (Bhatt et al., 2021). Trong khi đó, bộ dữ liệu UIT-DODV (Dieu et al., 2021) là bộ dữ liệu về tài liệu tiếng Việt đầu tiên với các đối tượng của hình ảnh đầu vào bao gồm “Caption”, “Table”, “Figure” và “Formula”. Đặc điểm của UIT-DODV là các trang tài liệu tiếng Việt, do đó mang lại nhiều tính mới mẻ. Ví dụ như cách trình bày các đối tượng ngữ nghĩa tạo ra nhiều khó khăn trong việc rút trích đặc trưng các thông tin, các công thức không chỉ là công thức toán học bình thường mà còn ở các dạng không thuộc toán học.
Thực nghiệm và đánh giá phương pháp YOLOX trên hai bộ dữ liệu IIIT-AR-13K cùng với UIT-DODV đã thu được những kết quả khá tốt. Đánh giá trên bộ dữ liệu UIT-DODV thì mô hình đạt được 69,0% mAP, kết quả này cao hơn 2,90% so với YOLOv4x-mish là mô hình one-stage đạt kết quả cao nhất được Dieu et al. (2021) công bố trước đó. Đánh giá trên bộ dữ liệu IIIT-AR-13K, mô hình đạt được 66,9% mAP, kết quả này thấp hơn so với các phương pháp two-stage Faster-RCNN và Mask[1]RCNN đã được công bố (Mondal et al., 2020).
nqhuy
Tạp chí Khoa học Trường Đại học Cần Thơ Tập 58, Số 3A (2022): 52-60