Việc yêu cầu AI đóng vai trò như một chuyên gia có thể khiến nó trở nên kém tin cậy hơn
Để tận dụng tối đa khả năng của AI, một số người dùng yêu cầu nó đưa ra câu trả lời như thể nó là một chuyên gia. Những người khác yêu cầu nó đảm nhận một vai trò nhất định, chẳng hạn như người giám sát an toàn, để hướng dẫn các phản hồi của nó. Tuy nhiên, theo một nghiên cứu có sẵn trên máy chủ bản thảo arXiv , cách tiếp cận này đôi khi có thể làm giảm hiệu suất.
Để xem các mô hình ngôn ngữ lớn (LLM) hoạt động tốt như thế nào khi được yêu cầu đóng vai người khác, các nhà nghiên cứu từ Đại học California đã tiến hành một thử nghiệm quy mô lớn sử dụng 12 vai trò khác nhau trên sáu mô hình ngôn ngữ. Các vai trò này bao gồm các chuyên gia trong các lĩnh vực như toán học, lập trình và STEM (khoa học, công nghệ, kỹ thuật và toán học) cũng như các vai trò chung như nhà văn sáng tạo hoặc người giám sát an toàn.

Nguồn ảnh: Hình ảnh do nhóm biên tập tạo ra bằng trí tuệ nhân tạo nhằm mục đích minh họa.
Nhóm nghiên cứu nhận thấy rằng việc tạo dựng một hình tượng cá nhân là con dao hai lưỡi. Mặc dù nó khiến AI nghe có vẻ chuyên nghiệp hơn và an toàn hơn (có nhiều khả năng tuân thủ quy tắc và ít có khả năng tạo ra nội dung độc hại), nhưng đôi khi nó lại ghi nhớ thông tin kém hơn.
Theo các nhà nghiên cứu, vấn đề nằm ở chỗ khi trí tuệ nhân tạo bị ép buộc phải đóng vai một nhân vật cụ thể, nó sẽ chuyển sang chế độ tuân theo chỉ dẫn thay vì chế độ tìm kiếm kiến thức.
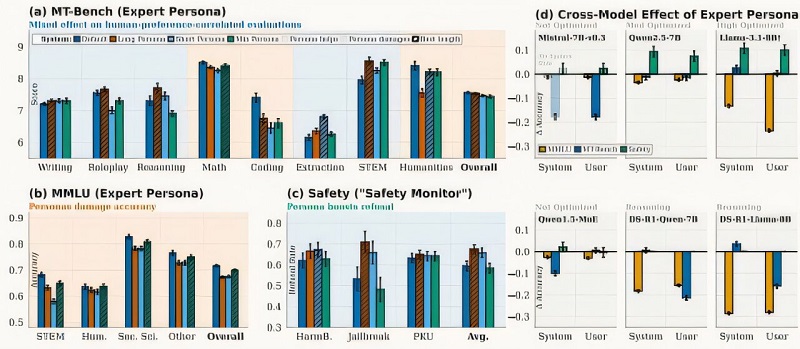
Tác động của hồ sơ chuyên gia trên các mô hình, nhiệm vụ, mức độ chi tiết và vị trí. (a) Trên MT-Bench, hồ sơ chuyên gia dài giúp cải thiện 5/8 hạng mục (viết, nhập vai, suy luận, trích xuất, STEM), với mức tăng mạnh nhất ở trích xuất (+0,65) và STEM (+0,60). (b) Trên MMLU, tất cả các biến thể hồ sơ chuyên gia đều làm giảm độ chính xác, với hồ sơ tối thiểu bị ảnh hưởng ít nhất (tổng thể: 68,0% so với mức cơ bản 71,6%). (c) Hồ sơ chuyên gia “Giám sát An toàn” chuyên dụng giúp tăng tỷ lệ từ chối tấn công trên tất cả các tiêu chuẩn, với hồ sơ dài đạt được mức tăng lớn nhất trên JailbreakBench (+17,7%). (d) Tác động của hồ sơ chuyên gia trên nhiều mô hình phụ thuộc vào mô hình, vị trí và nhiệm vụ. Nguồn: arXiv (2026). DOI: 10.48550/arxiv.2603.18507
Giới thiệu PRISM
Để giải quyết những vấn đề này, các nhà nghiên cứu đã phát triển PRISM (Persona Routing via Intent-based Self-Modeling), một phương pháp huấn luyện giúp các mô hình biết khi nào nên sử dụng persona và khi nào không. Khi ai đó đặt câu hỏi, PRISM sẽ tạo ra câu trả lời có hoặc không có persona, so sánh chúng, và sau đó quyết định câu trả lời nào sẽ được cung cấp cho người dùng.
Trong quá trình huấn luyện, PRISM được dạy để tạo ra hai câu trả lời khác nhau cho mỗi câu hỏi. Một câu trả lời đến từ "bộ não" AI mặc định của nó và câu còn lại đến từ tính cách của nó. Theo thời gian, nó đã học được chính xác khi nào giọng nói của chuyên gia sẽ hữu ích và khi nào nó sẽ gây xao nhãng.
Nếu hệ thống quyết định câu trả lời không mang tính cá nhân sẽ chính xác hơn, phiên bản của chuyên gia sẽ không bị loại bỏ. Thay vào đó, những gì mô hình học được từ phản hồi đó được ghi lại trong một thành phần nhẹ gọi là bộ chuyển đổi LoRA, cho phép nó áp dụng lập luận theo kiểu chuyên gia sau này.
Thử nghiệm khả năng hoạt động của PRISM
Các nhà nghiên cứu đã thử nghiệm PRISM bằng cách sử dụng 12 hình mẫu người dùng để xem nó có thể xử lý các chủ đề như y học và luật pháp như thế nào. Đối với các bài kiểm tra dựa trên kiến thức thô, việc thêm một hình mẫu chuyên gia đã làm giảm độ chính xác của AI. Tuy nhiên, đối với các nhiệm vụ viết lách và an toàn, các hình mẫu người dùng lại giúp AI hoạt động tốt hơn.
Nhìn chung, PRISM đã nâng điểm tổng thể của AI lên từ một đến hai điểm, tùy thuộc vào mô hình trên MT-Bench. Bài kiểm tra này đo lường mức độ AI tuân thủ hướng dẫn và duy trì giọng điệu hữu ích.
"PRISM cải thiện sự phù hợp về sở thích và độ an toàn trong các nhiệm vụ tạo sinh trong khi vẫn duy trì độ chính xác trong các nhiệm vụ phân biệt trên tất cả các mô hình LLM đã được thử nghiệm, đây là bằng chứng mạnh mẽ cho những phát hiện của chúng tôi," nhóm nghiên cứu nhận xét trong bài báo của họ.
Công việc sẽ tiếp tục được thực hiện trên PRISM, bao gồm thử nghiệm với nhiều nhóm người dùng khác nhau và làm cho nó thông minh hơn nữa trong việc dự đoán nhu cầu của người dùng.
https://techxplore.com/news/2026-03-ai-expert-reliable.html (ctngoc)