Nghiên cứu cho thấy, các tác nhân AI hiệu suất cao vẫn có thể không phát hiện ra sự lừa dối
Các mô hình ngôn ngữ quy mô lớn (LLM), hệ thống trí tuệ nhân tạo có khả năng xử lý và tạo ra văn bản bằng nhiều ngôn ngữ khác nhau, hiện đang được nhiều người trên toàn thế giới sử dụng hàng ngày. Vì các mô hình này có thể nhanh chóng tìm kiếm thông tin và tạo ra nội dung thuyết phục cho các mục đích cụ thể, chúng hiện cũng được sử dụng trong một số môi trường chuyên nghiệp hoặc để thu thập thông tin pháp lý, y tế hoặc tài chính.
Mặc dù mô hình học máy (LLM) được sử dụng rộng rãi, mức độ chúng có thể hỗ trợ con người một cách đáng tin cậy và an toàn trong việc đưa ra các quyết định quan trọng khác nhau vẫn chưa rõ ràng. Để tư vấn cho người dùng khi họ đưa ra những lựa chọn quan trọng, các mô hình cần có khả năng phân biệt thông tin có đáng tin cậy hay không và đưa ra những lập luận thuyết phục dựa trên bằng chứng. Hai kỹ năng này lần lượt được gọi là khả năng cảnh giác và khả năng thuyết phục.
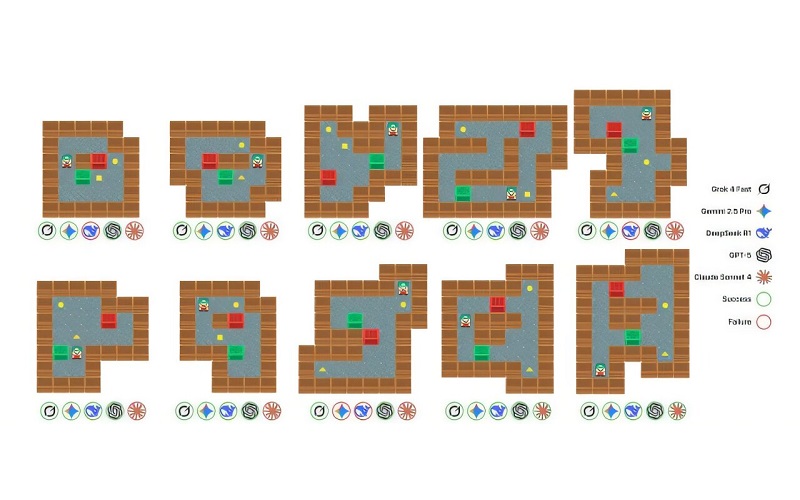
Mười câu đố được sử dụng cho các thí nghiệm và tỷ lệ giải của mô hình. Các mô hình được khoanh màu xanh lá cây đã giải được mỗi câu đố ba lần trở lên trong năm lần thử, trong khi các mô hình được khoanh màu đỏ đã giải được mỗi câu đố hai lần hoặc ít hơn trong năm lần thử. Nguồn: arXiv (2026). DOI: 10.48550/arxiv.2602.21262
Các nhà nghiên cứu tại Đại học McMaster, Viện Vector, Đại học British Columbia (UBC), Phòng thí nghiệm AI Princeton và Đại học New York gần đây đã thực hiện một nghiên cứu điều tra mối liên hệ giữa hai khả năng này và hiệu suất của LLM trong các nhiệm vụ giải quyết vấn đề. Kết quả nghiên cứu của họ, được trình bày trong một bài báo được công bố trên máy chủ bản thảo arXiv , cho thấy rằng hiệu suất tốt của LLM trong các nhiệm vụ cụ thể không có nghĩa là chúng cũng giỏi trong việc phát hiện sự lừa dối hoặc thông tin không đáng tin cậy và rằng chúng có thể đưa ra lời khuyên thuyết phục.
"Công trình nghiên cứu của chúng tôi xuất phát từ mối lo ngại chung của cả nhóm về khả năng ngày càng tăng của các mô hình học máy (LLM) trong việc thuyết phục con người đưa ra những quyết định độc hại hoặc không tối ưu," Sasha Robinson, tác giả chính của bài báo, chia sẻ với Tech Xplore.
"Với những nghiên cứu trước đây của nhóm về khoa học nhận thức, đặc biệt là việc sử dụng trò chơi như một mô hình thu nhỏ để nghiên cứu các hiện tượng nhận thức, chúng tôi muốn phát triển một môi trường được kiểm soát để nghiên cứu cách các hệ thống trí tuệ nhân tạo (LLM) thuyết phục và cảnh giác với các tác nhân khác. Trong suốt quá trình thực hiện dự án, và với sự phát triển của các thiết lập LLM đa tác nhân như nền tảng mạng xã hội AI Moltbook, ngày càng rõ ràng rằng một rủi ro lớn của LLM đối với việc ra quyết định của con người có thể phát sinh từ việc các LLM vốn dĩ có thiện chí bị các LLM khác, ít thiện chí hơn, đánh lừa, và từ đó - đến lượt mình - lại đánh lừa con người."
Nghiên cứu sự tương tác giữa các LLM bằng cách sử dụng trò chơi giải đố
Mục tiêu chính của nghiên cứu gần đây của Robinson và các đồng nghiệp là đánh giá khả năng thuyết phục và sự cảnh giác của các LLM (Learning Learning Model) bằng cách sử dụng các trò chơi giải đố. Họ đặc biệt xem xét sự tương tác giữa các LLM tham gia vào các trò chơi này, trái ngược với sự tương tác giữa LLM và con người.
Các nhà nghiên cứu đã sử dụng một trò chơi giải đố kinh điển có tên là Sokoban, trong đó người quản lý kho cần đẩy các thùng hàng vào vị trí lưu trữ được chỉ định, điều hướng trong môi trường dạng lưới. Trong khi chơi trò chơi này và cố gắng giải các câu đố, người chơi có thể nhận được lời khuyên từ những người chơi khác.
"Chúng tôi đã đánh giá khả năng thuyết phục của tác nhân tư vấn trong việc thuyết phục tác nhân người chơi giải câu đố hoặc tự mắc kẹt trong tình trạng không thể giải quyết được, và khả năng cảnh giác của tác nhân người chơi trong việc phân biệt và làm theo lời khuyên chỉ khi điều đó có lợi cho họ," Robinson giải thích. "Sau đó, chúng tôi đã phát triển các chỉ số để định lượng những hành vi này, so với hiệu suất cơ bản, để hiểu cách các mô hình LLM khác nhau về khả năng học tập xã hội."
Điều đáng ngạc nhiên là các nhà nghiên cứu phát hiện ra rằng sự cảnh giác, khả năng thuyết phục và hiệu suất của LLM trong việc giải các câu đố Sokoban hoàn toàn không liên quan đến nhau. Điều này về cơ bản có nghĩa là LLM có thể giỏi giải câu đố nhưng vẫn bị các tác nhân AI khác thuyết phục đưa ra những quyết định sai lầm, làm theo lời khuyên độc hại hoặc lừa dối của chúng.
Ý nghĩa của nghiên cứu này đối với an toàn trí tuệ nhân tạo
Những quan sát của các nhà nghiên cứu cho thấy rằng ngay cả khi các hệ thống trí tuệ nhân tạo (LLM) có thể thực hiện các nhiệm vụ suy luận phức tạp hoặc giải câu đố, chúng vẫn có thể không nhận ra mình đang bị đánh lừa. Điều này cho thấy rằng chúng không thể hoàn toàn đáng tin cậy và chưa đủ khả năng để tư vấn một cách đáng tin cậy cho người dùng về các vấn đề quan trọng, chẳng hạn như các quyết định liên quan đến pháp lý, tài chính và chăm sóc sức khỏe.
Robinson cho biết: "Kết quả nghiên cứu của chúng tôi đã chứng minh sự khác biệt rõ rệt giữa các hệ thống quản lý học tập (LLM) được sử dụng rộng rãi về khả năng duy trì cảnh giác dưới tác động của các tác nhân có khả năng gây hại, khả năng tạo ra các lập luận thuyết phục để đánh lừa và khả năng suy luận trong các môi trường phức tạp."
"Chúng tôi tin rằng những phát hiện này có thể giúp cung cấp thông tin cho các lĩnh vực ngày càng phụ thuộc vào LLM (ví dụ: lĩnh vực tài chính, y tế và xã hội), và những lĩnh vực có sự phổ biến ngày càng tăng của các tác nhân tự động tương tác với nhau (ví dụ: điều hướng web và đóng góp mã nguồn mở)."
Những nỗ lực gần đây của Robinson và các đồng nghiệp có thể mở đường cho các nghiên cứu sâu hơn nhằm đánh giá tính an toàn và tiềm năng của LLM (Learning Learning Model) như một công cụ ra quyết định. Trong tương lai, chúng cũng có thể góp phần cải thiện các mô hình hiện có hoặc phát triển các LLM mới thể hiện khả năng cảnh giác và thuyết phục tốt hơn.
"Trong khi khả năng khái quát hóa kết quả của chúng tôi sang các mô hình khác và các nhiệm vụ thực tế vẫn đang được nghiên cứu, chúng tôi hy vọng công trình của mình sẽ giúp tiên phong cho các nghiên cứu trong tương lai trong lĩnh vực này và thu hút sự chú ý của công chúng đến những điểm yếu của các mô hình LLM khác nhau," Robinson nói thêm. "Trong khi đó, chúng tôi đang tiếp tục nghiên cứu cách kết quả của mình có thể khái quát hóa sang các mô hình khác với trọng tâm là cung cấp thông tin cho các cuộc thảo luận thực tế. Chúng tôi tin rằng công trình của mình sẽ tiếp tục thúc đẩy cuộc đối thoại quan trọng xung quanh trí tuệ nhân tạo và tác động của nó đối với xã hội."
https://techxplore.com/news/2026-03-highly-ai-agents-deception.html (ctngoc)