Công cụ thiết kế protein dựa trên trí tuệ nhân tạo
Trí tuệ nhân tạo (AI) đã chứng minh khả năng đẩy nhanh quá trình phát triển thuốc và nâng cao hiểu biết của chúng ta về bệnh tật. Nhưng để biến AI thành các phương pháp điều trị mới, chúng ta cần đưa những mô hình tiên tiến và mạnh mẽ nhất vào tay các nhà khoa học.
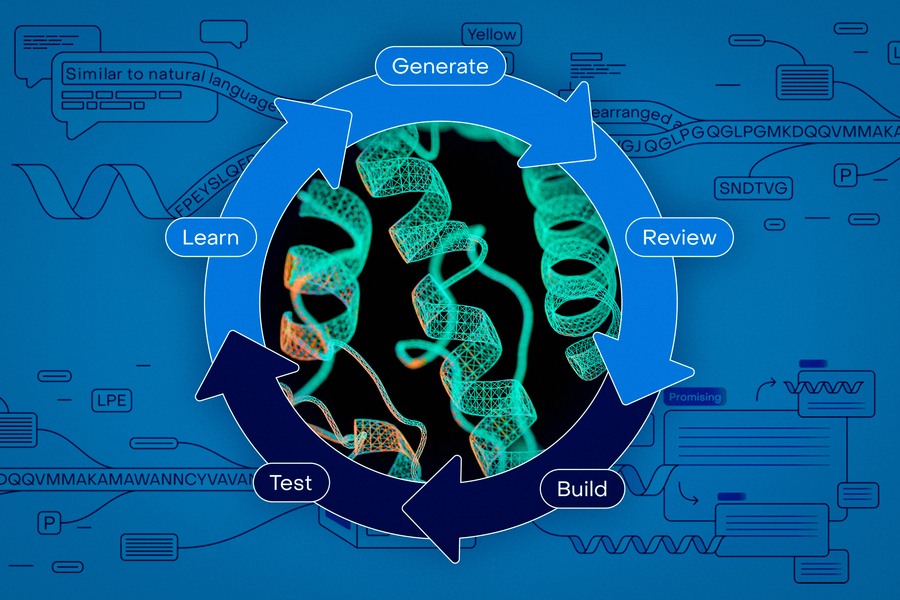
Vấn đề là hầu hết các nhà khoa học không phải là chuyên gia về máy học. Giờ đây, công ty OpenProtein.AI đang giúp các nhà khoa học luôn dẫn đầu trong lĩnh vực trí tuệ nhân tạo với một nền tảng không cần lập trình, cung cấp cho họ quyền truy cập vào các mô hình nền tảng mạnh mẽ và một bộ công cụ để thiết kế protein, dự đoán cấu trúc và chức năng protein, cũng như huấn luyện mô hình.
Công ty này, được thành lập bởi Tristan Bepler, tiến sĩ năm 2020 và cựu phó giáo sư MIT Tim Lu, tiến sĩ năm 2007, hiện đang trang bị cho các nhà nghiên cứu trong các công ty dược phẩm và công nghệ sinh học thuộc mọi quy mô các công cụ của mình, bao gồm cả các mô hình nền tảng được phát triển nội bộ cho kỹ thuật protein. OpenProtein.AI cũng cung cấp nền tảng của mình miễn phí cho các nhà khoa học trong giới học thuật.
“Đây thực sự là một thời điểm thú vị bởi vì những mô hình này không chỉ giúp kỹ thuật protein trở nên hiệu quả hơn - rút ngắn chu kỳ phát triển cho các liệu pháp điều trị và ứng dụng công nghiệp - mà còn có thể nâng cao khả năng thiết kế các protein mới với những đặc tính cụ thể”, Bepler nói. “Chúng tôi cũng đang xem xét việc áp dụng những phương pháp này cho các lĩnh vực phi protein. Nhìn chung, chúng tôi đang tạo ra một ngôn ngữ để mô tả các hệ thống sinh học”.
Thúc đẩy sự phát triển của sinh học bằng trí tuệ nhân tạo. Bepler đến MIT năm 2014 với tư cách là thành viên của Chương trình Tiến sĩ Sinh học Tính toán và Hệ thống, học tập dưới sự hướng dẫn của Bonnie Berger, Giáo sư Toán học Ứng dụng Simons của MIT. Chính tại đây, ông nhận ra rằng chúng ta hiểu biết rất ít về các phân tử cấu thành nên sinh học.
“Trước đây, chúng tôi chưa nghiên cứu kỹ các phân tử sinh học và protein để tạo ra các mô hình dự đoán chính xác về hoạt động của toàn bộ mạch gen, hoặc cách thức hoạt động của mạng lưới tương tác protein”, Bepler nhớ lại. “Điều đó đã khơi dậy sự quan tâm của tôi đến việc tìm hiểu protein ở mức độ chi tiết hơn”.
Bepler bắt đầu tìm hiểu các phương pháp dự đoán chuỗi axit amin cấu thành nên protein bằng cách phân tích dữ liệu tiến hóa. Điều này diễn ra trước khi Google phát hành AlphaFold, một mô hình dự đoán mạnh mẽ về cấu trúc protein. Công trình này đã dẫn đến một trong những mô hình trí tuệ nhân tạo tạo sinh đầu tiên để hiểu và thiết kế protein - mà nhóm nghiên cứu gọi là mô hình ngôn ngữ protein.
“Tristan đã giúp chúng tôi xây dựng các mô hình tính toán tốt hơn cho thiết kế sinh học. Chúng tôi cũng nhận ra rằng có sự thiếu kết nối giữa các công cụ tiên tiến nhất hiện có và các nhà sinh học, những người rất muốn sử dụng chúng nhưng lại không biết lập trình. OpenProtein ra đời từ ý tưởng mở rộng khả năng tiếp cận các công cụ này”. Bepler đã làm việc ở vị trí tiên phong trong lĩnh vực trí tuệ nhân tạo như một phần luận án tiến sĩ của mình. Ông biết rằng công nghệ này có thể giúp các nhà khoa học đẩy nhanh tiến độ công việc của họ.
“Chúng tôi bắt đầu với ý tưởng xây dựng một nền tảng đa năng để thực hiện kỹ thuật protein dựa trên học máy,” Bepler nói. “Chúng tôi muốn xây dựng một thứ gì đó thân thiện với người dùng vì các ý tưởng về học máy khá khó hiểu. Chúng đòi hỏi việc triển khai, GPU, tinh chỉnh, thiết kế thư viện trình tự. Đặc biệt vào thời điểm đó, đó là rất nhiều thứ mà các nhà sinh học cần phải học”.
Ngược lại, nền tảng của OpenProtein có giao diện web trực quan cho phép các nhà sinh học tải dữ liệu lên và thực hiện công việc kỹ thuật protein bằng máy học. Nó tích hợp nhiều mô hình mã nguồn mở, bao gồm PoET, mô hình ngôn ngữ protein hàng đầu của OpenProtein.
PoET, viết tắt của Protein Evolutionary Transformer (Bộ chuyển đổi tiến hóa protein), được huấn luyện trên các nhóm protein để tạo ra các tập hợp protein có liên quan. Bepler và các cộng sự đã chứng minh rằng nó có thể khái quát hóa về các ràng buộc tiến hóa đối với protein và kết hợp thông tin mới về trình tự protein mà không cần huấn luyện lại, cho phép các nhà nghiên cứu khác bổ sung dữ liệu thực nghiệm để cải thiện mô hình.
“Các nhà nghiên cứu có thể sử dụng dữ liệu của riêng họ để huấn luyện mô hình và tối ưu hóa trình tự protein, sau đó họ có thể sử dụng các công cụ khác của chúng tôi để phân tích các protein đó,” Bepler nói. “Mọi người đang tạo ra các thư viện trình tự protein trên máy tính và sau đó chạy chúng qua các mô hình dự đoán để có được sự xác thực và các dự đoán cấu trúc. Về cơ bản, đó là giao diện người dùng không cần lập trình, nhưng chúng tôi cũng có API dành cho những người muốn truy cập bằng mã”.
Các mô hình này giúp các nhà nghiên cứu thiết kế protein nhanh hơn, sau đó quyết định protein nào đủ triển vọng để tiến hành thử nghiệm thêm trong phòng thí nghiệm. Các nhà nghiên cứu cũng có thể nhập các protein quan tâm, và các mô hình có thể tạo ra các protein mới có tính chất tương tự.
Kể từ khi thành lập, đội ngũ của OpenProtein đã liên tục bổ sung các công cụ vào nền tảng của mình dành cho các nhà nghiên cứu bất kể quy mô phòng thí nghiệm hay nguồn lực của họ.
Công ty dược phẩm lớn Boehringer Ingelheim bắt đầu sử dụng nền tảng của OpenProtein vào đầu năm 2025. Gần đây, hai công ty đã công bố mở rộng hợp tác, theo đó nền tảng và mô hình của OpenProtein sẽ được tích hợp vào công việc của Boehringer Ingelheim trong việc thiết kế protein để điều trị các bệnh như ung thư và các bệnh tự miễn dịch hoặc viêm nhiễm.
Năm ngoái, OpenProtein cũng đã phát hành phiên bản mới của mô hình ngôn ngữ protein của mình, PoET-2, vượt trội hơn nhiều mô hình lớn hơn trong khi chỉ sử dụng một phần nhỏ tài nguyên tính toán và dữ liệu thực nghiệm.
Trong tương lai, các nhà sáng lập hy vọng sẽ tạo ra những mô hình có tính đến bản
Trong bối cảnh trí tuệ nhân tạo (AI) phát triển nhanh chóng, OpenProtein vẫn luôn coi sứ mệnh của mình là cung cấp cho các nhà khoa học những công cụ tốt nhất để phát triển các phương pháp điều trị mới nhanh hơn.